How to Use Our Tools
Complete step-by-step guides for merging, splitting, converting, and transforming Excel files and PDFs. Every feature explained in detail.
Merge Excel Files
Combine multiple Excel spreadsheets (XLS, XLSX, CSV) into one file with smart column matching, conflict resolution, and 100% privacy.
드래그 앤 드롭 또는 클릭하여 선택
홈 페이지의 드래그 앤 드롭 영역을 사용하여 두 개 이상의 엑셀 파일을 업로드하세요. XLS(Excel 97-2003), XLSX(Excel 2007+), CSV 파일을 업로드할 수 있으며, 다른 형식을 혼합할 수도 있습니다. 업로드된 파일은 이름, 크기, 감지된 시트와 함께 표시됩니다. 그립 핸들을 드래그하여 파일 순서를 변경하거나 삭제 버튼으로 개별 파일을 제거할 수 있습니다.
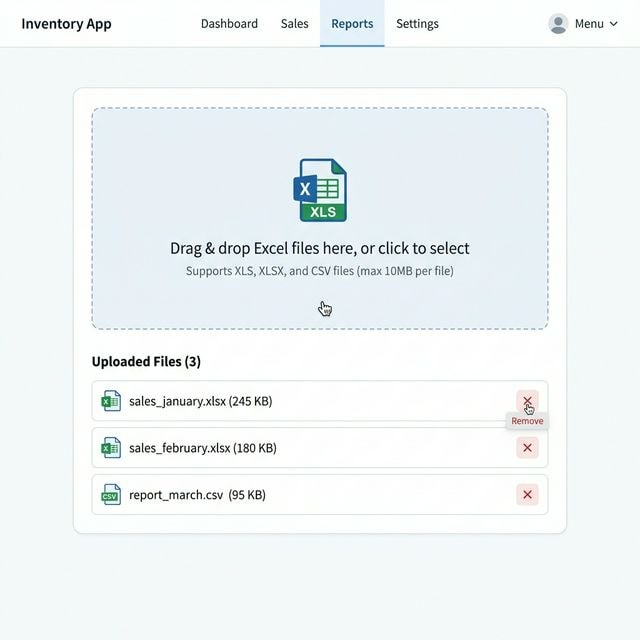
판매 보고서, 설문 응답, 데이터베이스 내보내기 등 다양한 출처의 파일을 업로드할 수 있습니다 — XLS, XLSX, CSV 형식이면 됩니다.
파일 합치는 방법 선택
오른쪽 패널에서 세 가지 병합 모드 중 하나를 선택하세요: 단일 스프레드시트는 모든 데이터를 하나의 연속 시트에 쌓습니다. 다중 시트는 각 파일을 하나의 워크북에서 별도 탭으로 배치합니다. 선택적 병합은 각 워크북에서 특정 시트를 선택할 수 있습니다.
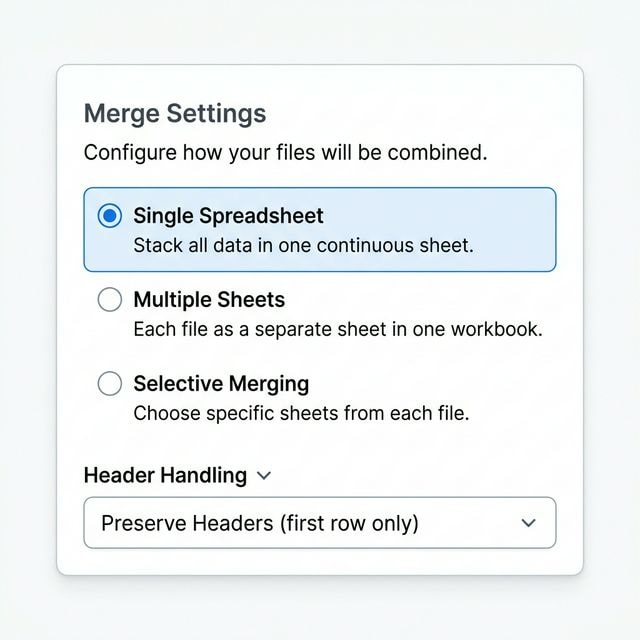
모든 파일이 동일한 열 구조를 가진 경우 단일 스프레드시트를 사용하세요. 소스 파일별로 데이터를 분리하려면 다중 시트를 사용하세요.
헤더 처리, 데이터 범위, 서식 미세 조정
고급 옵션으로 병합 방식을 맞춤 설정하세요. 헤더 처리를 선택하여 열 헤더 처리 방법을 제어합니다. 사용자 정의 데이터 범위를 설정하여 각 파일의 특정 부분만 병합할 수 있습니다. 서식 유지를 활성화하여 원본 셀 스타일과 색상을 유지하세요.
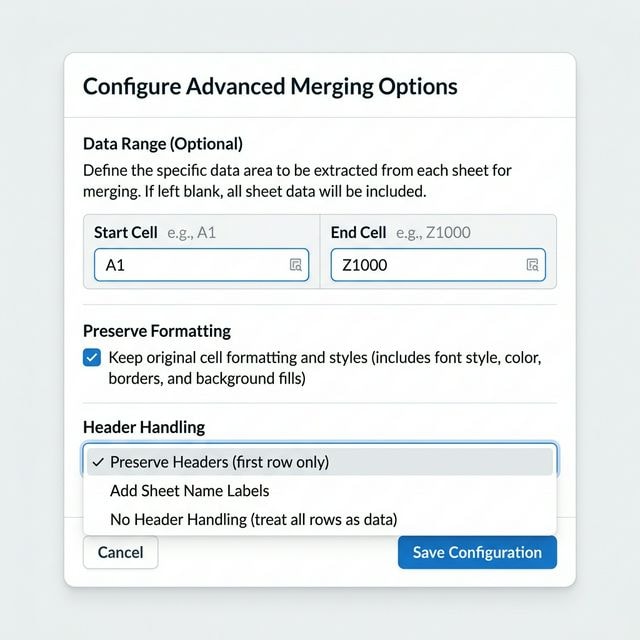
파일의 첫 번째 행에 헤더가 있는 경우, 병합 출력에서 헤더 행이 중복되지 않도록 항상 '헤더 유지'를 사용하세요.
스마트 매칭으로 다른 열 구조 정렬
단일 스프레드시트 모드로 병합할 때, 도구는 모든 파일의 열 헤더를 자동으로 분석합니다. 열이 정확히 일치하지 않는 경우 — 예를 들어 한 파일의 '고객명'과 다른 파일의 '클라이언트명' — 열 불일치 대화 상자가 나타납니다. 드롭다운 메뉴를 사용하여 열을 수동으로 매핑하거나, 그대로 계속을 클릭하여 재매핑 없이 병합할 수 있습니다.
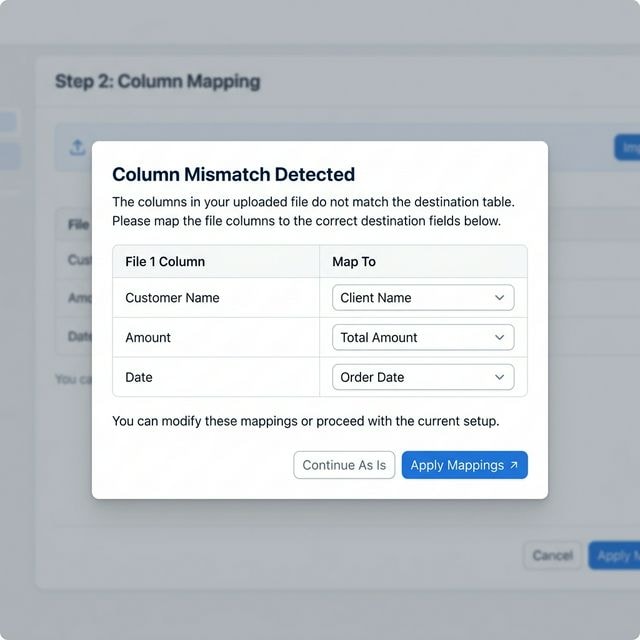
열 충돌 해결은 단일 스프레드시트 모드에서만 나타납니다. 충돌을 완전히 피하려면 다중 시트 모드를 사용하세요.
다중 시트 워크북에서 포함할 시트 선택
다중 시트 엑셀 파일을 업로드하면, 병합 옵션 아래에 시트 선택 패널이 나타납니다. 각 파일에서 개별 시트를 체크하거나 해제하여 병합에 포함하거나 제외할 수 있습니다. 전체 및 없음 버튼을 사용하여 빠르게 선택할 수 있습니다.

워크북에 요약 시트, 차트, 메타데이터 시트가 포함되어 있어 병합 출력에 원하지 않는 경우 특히 유용합니다.
클릭하여 합쳐진 파일을 즉시 받기
모든 설정이 완료되면 파일 합치기 버튼을 클릭하세요. 도구는 브라우저에서 로컬로 모든 파일을 처리합니다 — 서버에 업로드되지 않습니다. 병합이 완료되면 녹색 성공 배너가 나타나고 다운로드 버튼이 활성화됩니다. 다운로드를 클릭하여 병합된 XLSX 파일을 저장하세요.
출력은 항상 Excel, Google Sheets 및 기타 스프레드시트 애플리케이션과 최대 호환성을 위해 최신 XLSX 파일로 저장됩니다.
병합 모드 설명
시나리오에 맞는 올바른 병합 모드를 선택하세요
단일 스프레드시트
모든 파일의 데이터를 하나의 연속 시트에 쌓습니다. 월간 보고서, 설문 배치와 같이 동일한 열 구조를 가진 파일을 결합하는 데 이상적입니다. 첫 번째 파일의 헤더가 보존되고 스마트 열 매칭이 데이터를 자동으로 정렬합니다.
적합: 월간 보고서, 설문 데이터, 유사 구조 내보내기
다중 시트
각 업로드된 파일을 하나의 워크북 내에 별도의 이름이 지정된 탭으로 배치합니다. 각 파일의 원본 데이터 구조가 완전히 보존됩니다. 데이터를 혼합하지 않고 하나의 워크북으로 통합하려는 경우 적합합니다.
적합: 소스별 파일 정리, 여러 보고서 보관
선택적 병합
각 워크북에서 병합에 포함할 시트를 완전히 제어할 수 있습니다. 다중 시트 엑셀 파일을 업로드하고 필요한 시트만 직접 선택하세요. 선택 해제된 시트는 완전히 건너뜁니다.
적합: 다중 시트 워크북, 특정 데이터 추출
고급 옵션 가이드
병합 프로세스의 모든 측면을 미세 조정하세요
헤더 처리
병합 중 열 헤더 처리 방법을 제어합니다. '헤더 유지'는 첫 번째 파일의 헤더 행만 유지하여 중복을 방지합니다. '시트 라벨 추가'는 각 파일 데이터 앞에 소스 시트 이름을 삽입합니다. '처리 없음'은 특별한 헤더 논리 없이 모든 행을 동일하게 처리합니다.
데이터 범위
특정 셀 범위로 병합을 제한합니다. 시작 셀(예: A1)과 끝 셀(예: Z1000)을 입력하여 각 파일의 일부만 추출하세요. 파일에 메인 데이터 영역 외의 메타데이터나 메모가 포함된 경우 유용합니다.
서식 유지
소스 파일의 원본 셀 서식, 색상, 글꼴 스타일, 조건부 서식을 병합 출력에 유지합니다. 비활성화하면 원시 데이터 값만 전송됩니다.
PDF to Excel Converter
Extract tables and data from PDF documents into clean, editable Excel spreadsheets. Smart table detection with multiple extraction modes.
Drag and drop or click to select a PDF
Start by uploading your PDF file using the drag-and-drop zone. The tool accepts standard PDF files up to 50 MB. Once uploaded, the file name, size, and PDF badge are displayed. If your PDF is password-protected, a password field will appear automatically — just enter the password to unlock it.
For best results, use PDFs with clearly structured tables rather than scanned images. Scanned PDFs may produce lower-quality results. For scanned documents, try our Image to Excel (OCR) tool instead.
Choose extraction mode, output format, and options
In the options panel on the right, configure how your PDF data should be extracted. Choose from three Extraction Modes: Auto (automatically detects tables and text), Table Mode (optimized for structured tabular data), or Lines Mode (extracts text line by line). Select your Output Format — XLSX for Excel or CSV for plain text. Set a Page Range (e.g., "1-3, 5") to convert only specific pages. Choose a Delimiter (Auto, Tab, Pipe, Comma, Semicolon, or Space) to control how columns are separated. Enable "Sheet per page" to place each PDF page into a separate Excel sheet tab.
Use "Auto" extraction mode for most PDFs — it intelligently detects whether the content is a table or plain text. Use "Table" mode only when you know the PDF contains structured tabular data with clear rows and columns.
Check the extracted data before converting
Click the "Preview" button to see a preview of the extracted data before committing to the full conversion. The preview shows a paginated table view with row counts, column counts, and total pages detected. This lets you verify the extraction quality and adjust settings if needed before downloading.
Always preview first when working with complex PDFs that have mixed content (tables, paragraphs, headers). This saves time by letting you adjust settings before the full conversion.
Process and download your Excel file
Click the "Convert Now" button to process the full PDF conversion. A progress indicator shows the conversion status. Once complete, a green success banner appears with the conversion time. Click the "Download" button to save your converted XLSX or CSV file. The output file name is automatically generated from your original PDF name with a timestamp.
The converted XLSX file is compatible with Microsoft Excel, Google Sheets, LibreOffice Calc, and all major spreadsheet applications.
Key Features
Smart Table Detection
Automatically detects tables in your PDF and extracts structured data into clean spreadsheet columns.
3 Extraction Modes
Auto, Table, and Lines modes let you choose the best extraction method for your PDF content.
Password Support
Unlock and convert password-protected PDFs by entering the document password.
Page Range Selection
Convert only specific pages (e.g., "1-3, 5") instead of the entire document.
Sheet Per Page
Place each PDF page into a separate Excel sheet tab for organized output.
Preview Before Download
Check extracted data in a table preview before committing to the full conversion.
Excel Splitter
Split large Excel files into smaller pieces with 9 powerful split modes — by rows, sheets, columns, formulas, dates, file size, and more.
Drag and drop or click to upload XLS, XLSX, or CSV
Upload a single Excel or CSV file using the drag-and-drop zone at the top of the page. The tool accepts XLS, XLSX, and CSV formats. Once uploaded, a step progress bar updates to show you are in the "Configure" phase. The file info panel shows the file name, detected sheets, total rows, and columns.
For very large files (50,000+ rows), close other browser tabs to free up memory. All processing happens locally in your browser, so performance depends on your device.
Choose from 9 powerful split modes
Use the Split Configuration panel on the right to choose how your file should be split. The tool offers 9 split modes: By Fixed Rows (split every N rows), By File Count (divide into N equal files), By Sheet (each sheet as a separate file), By Column Value (group rows by a column's value), By Blank Rows (split at empty rows), By File Size (limit each output file's size), By Formula Type (separate formula cells from value cells), By Expression (custom conditions), and By Date Range (time-based groups). Each mode has its own configuration options that appear when selected.
The "By Column Value" mode is incredibly powerful for splitting sales data by region, employee records by department, or survey responses by category — any column with repeating group values.
Refine your data and save split configurations
Use the Data Filters panel to narrow down which rows are included before splitting. You can filter by column values, exclude empty rows, or set conditions. The Template Manager lets you save your split configuration as a reusable template — perfect for recurring tasks like monthly report splitting. Simply save a template, and load it next time to apply the same settings instantly.
Save templates for split configurations you use regularly. For example, create a "Monthly Sales Split" template that splits by the "Region" column and filters for the current month.
Check your data before splitting
Switch between four tabs below the upload area: Preview (see your data in a table), Results (view split output after processing), Statistics (column stats, value distributions, data type breakdowns), and Formulas (detect and inspect Excel formulas). The Preview tab shows your raw data with pagination and column headers. The Statistics tab gives you a powerful analytical overview of your dataset.
Use the Formulas tab to check if your file contains Excel formulas before splitting. The tool preserves formulas across split files, but it is good to know what formulas are present.
Process your file and download results
Click the "Split Now" button to process your file. The step progress bar updates to show the "Split" phase, and then moves to "Results" when complete. Switch to the Results tab to see all generated files. You can download individual files or download all files at once as a ZIP archive. Each output file is named based on your split criteria (e.g., by column value or row range).
You can click "New File" at any time to reset and upload a different file. Your split configuration and templates are preserved.
9 Supported Split Modes
By Fixed Rows
Split every N rows — perfect for breaking large datasets into manageable chunks.
By File Count
Divide into N equal files — ideal when you need a specific number of output files.
By Sheet
Each sheet becomes a separate file — great for multi-sheet workbooks.
By Column Value
Group rows by a column value — perfect for categorizing data by region, department, etc.
By Blank Rows
Split at empty rows — useful for data with natural section breaks.
By File Size
Limit each output file size — handy when email or system upload limits apply.
By Formula Type
Separate formula cells from value cells — useful for data auditing.
By Expression
Custom conditions and expressions — maximum flexibility for power users.
By Date Range
Time-based groups — split data by week, month, quarter, or year.
Excel to JSON Converter
Convert Excel (XLS, XLSX) and CSV files to structured JSON with advanced options for nested objects, type parsing, and custom formatting.
Drag and drop or click to select a file
Upload a single Excel (XLS, XLSX) or CSV file using the drag-and-drop zone. The tool processes files entirely in your browser — nothing is uploaded to any server. Once a file is uploaded, the tool automatically detects all available sheets and displays them in the options panel. The file name and size are shown below the upload area.
This tool processes everything locally using the SheetJS library. Your data never leaves your device, making it safe for sensitive financial or personal data.
Choose format, indentation, and data parsing rules
In the options panel on the right, configure your JSON output. Select which Sheets to process by checking/unchecking individual sheets. Choose a Structure Format: Flat Array (array of row objects — best for APIs), Object Dictionary (object with sheet names as keys — for multi-sheet files), or Wrapped Root ({ data: ... } wrapper — for frameworks). Pick Indentation: 2 spaces (readable), 4 spaces (more spaced), or Minified (smallest file size). Set Empty Cells handling: Omit (skip empty cells), Null (set to null), or Empty String (set to "").
Use "Flat Array" format for single-sheet files when you need clean API-ready JSON. Use "Object Dictionary" when your file has multiple sheets and you want to preserve the sheet structure.
Control nested objects, type parsing, and date formats
Toggle three advanced data parsing options: Nested Objects — when enabled, column headers with dots (like "address.city") are converted into nested JSON objects ({ address: { city: "..." } }). Auto-Parse Types — keeps numbers, booleans, and dates as their native types instead of converting everything to strings. Raw Date Format — when enabled, preserves Excel's internal date serial numbers instead of converting to JavaScript Date objects.
Enable "Nested Objects" if your column headers use dot notation (e.g., "user.name", "user.email") — the tool will automatically create nested JSON structures from flat spreadsheet columns.
Process your file and get JSON output
Click the "Convert Now" button to generate JSON from your spreadsheet. The output appears in a syntax-highlighted preview panel below, showing the first 5,000 characters. The file size of the generated JSON is displayed. Click "Download" to save the JSON file. The downloaded file name matches your original file name with a .json extension.
You can copy the JSON directly from the preview panel for quick use. For large files, the preview is truncated but the full JSON is included in the download.
Key Features
Multiple Output Formats
Flat Array, Object Dictionary, or Wrapped Root — choose the best structure for your use case.
Nested Object Support
Column headers with dots are converted to nested JSON objects automatically.
Sheet Selection
Choose which sheets to include — process one sheet or all sheets at once.
Type Preservation
Numbers, booleans, and dates are preserved as native JSON types, not strings.
Minified or Pretty
Choose 2-space, 4-space, or minified indentation for your output.
100% Client-Side
All processing happens in your browser. Your data never leaves your device.
Mail Merge Generator
Generate bulk personalized letters, emails, and documents from Excel or CSV data using {{Tag}} placeholders. Export as TXT, HTML, or PDF.
Upload an Excel or CSV file with your records
Upload an Excel (XLS, XLSX) or CSV file containing your data records. The tool reads the first sheet and displays all detected columns. A data table preview shows all your records with column headers. You can search and filter records using the search bar above the table. The record count is displayed showing matching vs. total records. Don't have a file? Click "Try Demo" to load sample customer data instantly and explore the tool.
Make sure your column headers are in the first row. Trailing spaces in column names are automatically trimmed. The tool reads the first sheet of multi-sheet workbooks.
Create a rich-text template with {{Tags}} for personalization
Write your document template in the rich-text editor. Insert data placeholders by clicking column name buttons below the editor — each click inserts a {{ColumnName}} tag at the cursor position. The editor supports rich text formatting: Bold, Italic, Underline, Headings (H1, H2), Paragraph, Bullet Lists, Numbered Lists, Text Alignment (Left/Center/Right), Text Color, and Clear Formatting. You can also add a Subject Line Template for email drafts. Use {{#if Status}} conditional {{/if}} blocks for conditional content. Insert dynamic QR codes with {{qr ColumnName}} and dynamic images with {{img ImageURLColumn}}.
Your template is automatically saved to localStorage — so even if you close the browser, your template is preserved when you return. Click "Load Demo Template" to see an example template.
See live previews of each personalized document
The Preview panel on the right shows a live, rendered preview of your template merged with actual data. Use the left/right navigation arrows to cycle through all records and see how each personalized document looks. The preview renders rich text, images, and QR codes in real-time. You can also preview the Subject Line merged with the current record. Copy the rendered body to clipboard with "Smart Copy" (preserves HTML formatting), copy the subject line separately, or click "Open in Email App" to launch your default email client with the preview pre-filled.
Use "Smart Copy (Email Body)" to copy the rendered HTML to your clipboard — it preserves bold, italic, lists, and formatting when pasted into email clients like Gmail or Outlook.
Choose output format, filename pattern, and generate documents
In the Download section, choose your output format: TXT (plain text), HTML (rich formatted), or PDF (printable documents). Set a Filename Pattern using {{Tags}} — for example, "invoice_{{Name}}.html" generates unique filenames for each record. The {{row}} tag inserts the row number. Click "Generate & Download ZIP" to create all documents at once. A real-time progress bar shows generation status. Once complete, the ZIP file downloads automatically containing all personalized documents. The ZIP file size is displayed after generation.
PDF generation uses html2canvas for high-quality rendering. For large datasets (100+ records), TXT and HTML formats are significantly faster than PDF because each PDF requires rendering.
Power Features
Rich Text Editor
Full formatting toolbar — bold, italic, headings, lists, alignment, colors, and more.
{{Tag}} Placeholders
Click column names to insert personalization tags at the cursor position.
Conditional Logic
Use {{#if}} blocks to show/hide content based on data values.
Dynamic QR Codes
Generate QR codes from any data column using {{qr ColumnName}}.
Dynamic Images
Embed images from URL columns using {{img ImageURLColumn}}.
Multi-Format Output
Export as TXT, HTML, or PDF — all delivered in a ZIP archive.
Live Preview
See each personalized document rendered in real-time with record navigation.
Auto-Save Templates
Templates are saved to localStorage and persist across browser sessions.
Template Quick Reference
Conditional Logic
{{#if Status}}Paid{{/if}}{{#unless Paid}}Overdue{{/unless}}Dynamic QR Code
{{qr Email}} → generates QR imageDynamic Image
{{img PhotoURL}} → embeds imageImage to Excel (OCR)
Extract text and tables from images using OCR technology. Convert photos, screenshots, receipts, and scanned documents to Excel spreadsheets.
Drag and drop or click to select image files
Upload one or more images using the drag-and-drop zone. Supported formats include PNG, JPG/JPEG, WebP, BMP, and TIFF. You can upload multiple images at once (up to 20 MB each). Uploaded images are displayed as thumbnails with file name and size. Remove individual images with the delete button, or clear all images to start over. The tool processes images entirely in your browser using Tesseract.js OCR.
For best OCR accuracy, use clear, high-resolution images with good contrast. Screenshots of spreadsheets work very well. Blurry or low-resolution photos may produce lower-quality results.
Choose language, extraction mode, and enhancement options
In the options panel, configure your OCR settings. Select the OCR Language from 20+ supported languages including English, Hindi, German, French, Spanish, Japanese, Korean, Chinese (Simplified/Traditional), Arabic, and more. Choose an Extraction Mode: Table (detects and reconstructs table grid from word positions) or Lines (extracts text line by line). Select Output Format: XLSX or CSV. Enable "Sheet per Image" to place each image's data on a separate Excel sheet. Toggle Image Enhancement to preprocess images for better OCR accuracy — with three strength levels (Low, Medium, High). Enable Auto-Upscale to automatically enlarge small images for improved text recognition.
Always enable Image Enhancement for photos and scanned documents. The preprocessing pipeline applies grayscale conversion, contrast adjustment, and Otsu's binarization — dramatically improving OCR accuracy.
Run OCR and review extracted data with confidence scores
Click "Convert to Excel" to start the OCR process. A progress indicator shows the current status: loading language model, enhancing image, and recognizing text — with per-image progress. Once complete, extracted data is displayed in a table preview with per-cell confidence color coding: Green (≥80% confidence — high accuracy), Yellow (50-80% — may need review), and Red (<50% — likely needs correction). You can click any cell to edit its content inline — corrections are applied instantly. The overall confidence score and conversion time are displayed.
Pay special attention to cells with yellow or red confidence highlights — these are the most likely to contain OCR errors. Click directly on any cell to correct the text before downloading.
Download the converted spreadsheet
Click "Download" to save the converted file as XLSX or CSV. If you enabled "Sheet per Image" with multiple images, each image's data appears on its own named sheet tab. Column widths are automatically adjusted to fit the content. If you edited any cells after OCR, click "Regenerate File" to update the download with your corrections before saving.
Use "Sheet per Image" when converting multiple related images (like multi-page scanned documents) to keep each page's data organized in separate tabs within one workbook.
OCR Features
20+ Languages
English, Hindi, German, French, Spanish, Japanese, Korean, Chinese, Arabic, and many more.
Smart Table Reconstruction
Spatial analysis of word positions reconstructs table grids from images.
Image Enhancement
Grayscale conversion, contrast adjustment, and Otsu's binarization for better accuracy.
Auto-Upscale
Automatically enlarges small images for improved text recognition.
Inline Cell Editing
Click any extracted cell to correct text directly before downloading.
Confidence Scoring
Per-cell color coding shows OCR confidence — green, yellow, or red.
Multi-Image Batch
Process multiple images at once with optional sheet-per-image output.
100% Client-Side
Tesseract.js runs entirely in your browser. No image uploads to any server.
Supported Image Formats
Maximum file size: 20 MB per image. Multiple images can be processed at once.
최상의 결과를 위한 프로 팁
가장 깔끔한 단일 스프레드시트 병합을 위해 모든 파일이 동일한 열 순서와 이름을 사용하도록 하세요.
큰 파일? 다른 브라우저 탭을 닫아 빠른 처리를 위한 메모리를 확보하세요.
그립 핸들을 드래그하여 파일 순서를 변경하세요 — 병합 순서는 파일 목록 순서를 따릅니다.
단일 병합 작업에서 XLS, XLSX, CSV 파일을 혼합할 수 있습니다.
모든 처리는 브라우저에서 이루어집니다 — 파일은 기기를 떠나지 않습니다.
데이터 범위 옵션을 사용하여 지저분한 스프레드시트의 헤더 행이나 추가 내용을 건너뛰세요.